The frenchdata package provides functions to download
the finance data sets provided by the data
library website of Prof. Kenneth French.
We can visit the website using the function:
this will open the page on your default browser.
As a first step we get the list of data sets that are currently available to download:
data_sets <- get_french_data_list()The get_french_data_list() function returns an object of
the S3 class french_data_list:
data_sets
#>
#> ── Kenneth's French data library
#> ℹ Information collected from: https://mba.tuck.dartmouth.edu/pages/faculty/ken.french/data_library.html on Wed Sep 08 20:48:59 2021
#>
#> ── Files list
#> # A tibble: 297 × 3
#> name file_url details_url
#> <chr> <chr> <chr>
#> 1 Fama/French 3 Factors ftp/F-F… Data_Libra…
#> 2 Fama/French 3 Factors [Weekly] ftp/F-F… Data_Libra…
#> 3 Fama/French 3 Factors [Daily] ftp/F-F… Data_Libra…
#> 4 Fama/French 5 Factors (2x3) ftp/F-F… Data_Libra…
#> 5 Fama/French 5 Factors (2x3) [Daily] ftp/F-F… Data_Libra…
#> 6 Portfolios Formed on Size ftp/Por… Data_Libra…
#> 7 Portfolios Formed on Size [ex.Dividends] ftp/Por… Data_Libra…
#> 8 Portfolios Formed on Size [Daily] ftp/Por… Data_Libra…
#> 9 Portfolios Formed on Book-to-Market ftp/Por… Data_Libra…
#> 10 Portfolios Formed on Book-to-Market [ex. Dividends] ftp/Por… Data_Libra…
#> # … with 287 more rowsSearching for a data set
To download a data set we need to identify its name first from the
list data_sets obtained previously. A simple way of
performing this search is to use the View() function
provided by RStudio on the files_list element that contains
the the files list:
View(data_sets$files_list)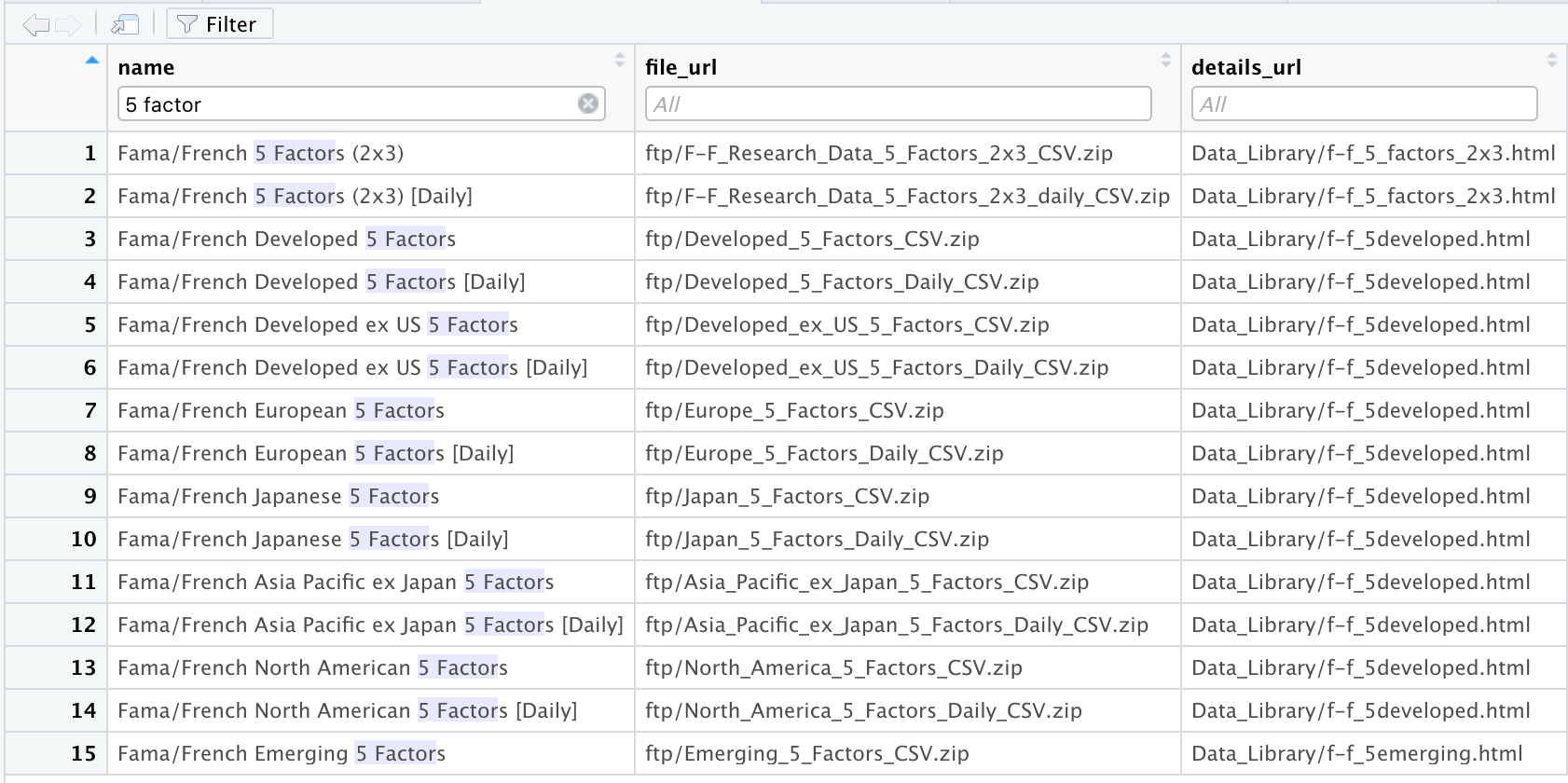
and use the filter to narrow down the search, for instance if I’m looking for the 5 factors I can quickly identify the correct data set name.
Downloading a data set
To download a specific data, for instance the monthly Fama/French 5 Factors (2x3) set we can use:
ff_5_factors <-
download_french_data("Fama/French 5 Factors (2x3)")
#> New names:
#> * `` -> ...1
#> New names:
#> * `` -> ...1This will return an object of class french_dataset:
ff_5_factors
#>
#> ── Kenneth's French data set
#> ℹ This file was created by CMPT_ME_BEME_OP_INV_RETS using the 202106 CRSP database. The 1-month TBill return is from Ibbotson and Associates Inc.
#>
#> Information collected from: https://mba.tuck.dartmouth.edu/pages/faculty/ken.french/ftp/F-F_Research_Data_5_Factors_2x3_CSV.zip on Wed Sep 08 20:57:17 2021
#>
#> ℹ For details on the data set call the function `browse_details_page()` on this object
#>
#> ── Subsets in the file:
#> # A tibble: 2 × 2
#> name data
#> <chr> <list>
#> 1 "" <spec_tbl_df [696 × 7]>
#> 2 "Annual Factors: January-December" <spec_tbl_df [57 × 7]>The file contains two subsets of data:
ff_5_factors$subsets
#> # A tibble: 2 × 2
#> name data
#> <chr> <list>
#> 1 "" <spec_tbl_df [696 × 7]>
#> 2 "Annual Factors: January-December" <spec_tbl_df [57 × 7]>The first one is the default one and is unnamed, and the second one is on “Annual Factors: January-December”. We can access the data on the first subset:
monthly_ff_5_factors <- ff_5_factors$subsets$data[[1]]
monthly_ff_5_factors
#> # A tibble: 696 × 7
#> date `Mkt-RF` SMB HML RMW CMA RF
#> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
#> 1 196307 -0.39 -0.45 -0.94 0.66 -1.15 0.27
#> 2 196308 5.07 -0.82 1.82 0.4 -0.4 0.25
#> 3 196309 -1.57 -0.48 0.17 -0.76 0.24 0.27
#> 4 196310 2.53 -1.3 -0.04 2.75 -2.24 0.29
#> 5 196311 -0.85 -0.85 1.7 -0.45 2.22 0.27
#> 6 196312 1.83 -1.9 -0.06 0.07 -0.3 0.29
#> 7 196401 2.24 0.08 1.53 0.22 1.5 0.3
#> 8 196402 1.54 0.31 2.86 0.06 0.85 0.26
#> 9 196403 1.41 1.4 3.37 -2.01 2.93 0.31
#> 10 196404 0.1 -1.5 -0.66 -1.35 -1.08 0.29
#> # … with 686 more rowsWe can now browse use this data.frame directly, for instance, to plot all each of the factors and the risk-free rate overtime:
monthly_ff_5_factors %>%
mutate(date = ym(date)) %>%
pivot_longer(cols = -date,
names_to = "factor",
values_to = "value") %>%
ggplot(data = .,
mapping = aes(x = date, y = value,
group = factor,
color = factor)) +
geom_line() +
labs(caption = "Source: Kenneth French Data Library") +
facet_wrap( ~ factor)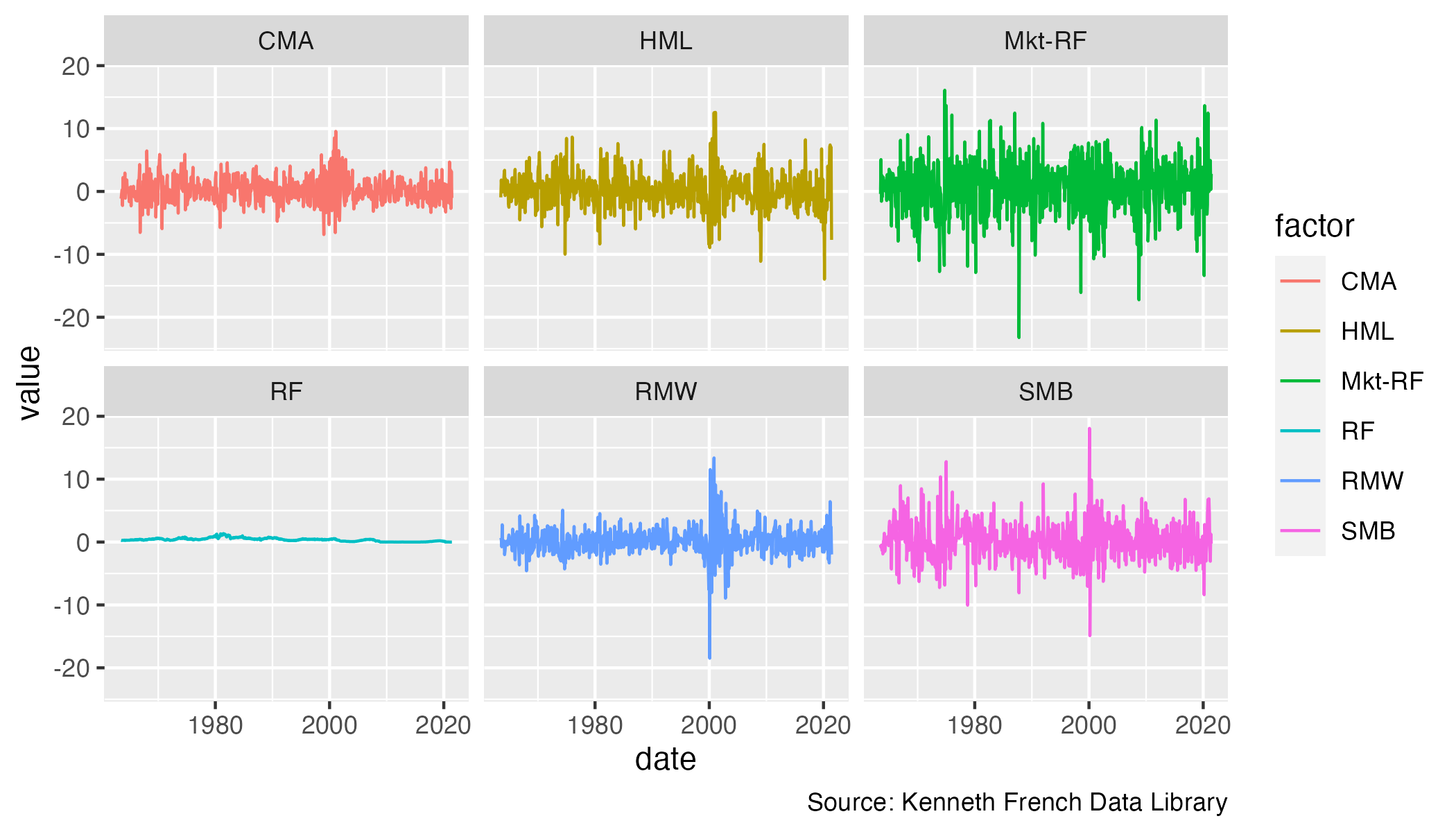
We can browse the details page for this specific data set using:
browse_details_page(ff_5_factors)Downloading and saving a data set
We can also save the original uncompressed file when downloading and reading it, by specifying a valid path name:
ff_5_factors <-
download_french_data("Fama/French 5 Factors (2x3)",
dir = ".",
dest_file = "fama_french_5_factors.zip")This will download the file, read it, assign the result to the object
ff_5_factors, and save the results to the file
fama_french_5_factors.zip on the current directory.
If we prefer to use the original file name just leave the
dest_file parameter unset:
ff_5_factors <-
download_french_data("Fama/French 5 Factors (2x3)",
dir = ".")